手把手:用 Claude Code + Obsidian 搭一个自己会维护的知识库
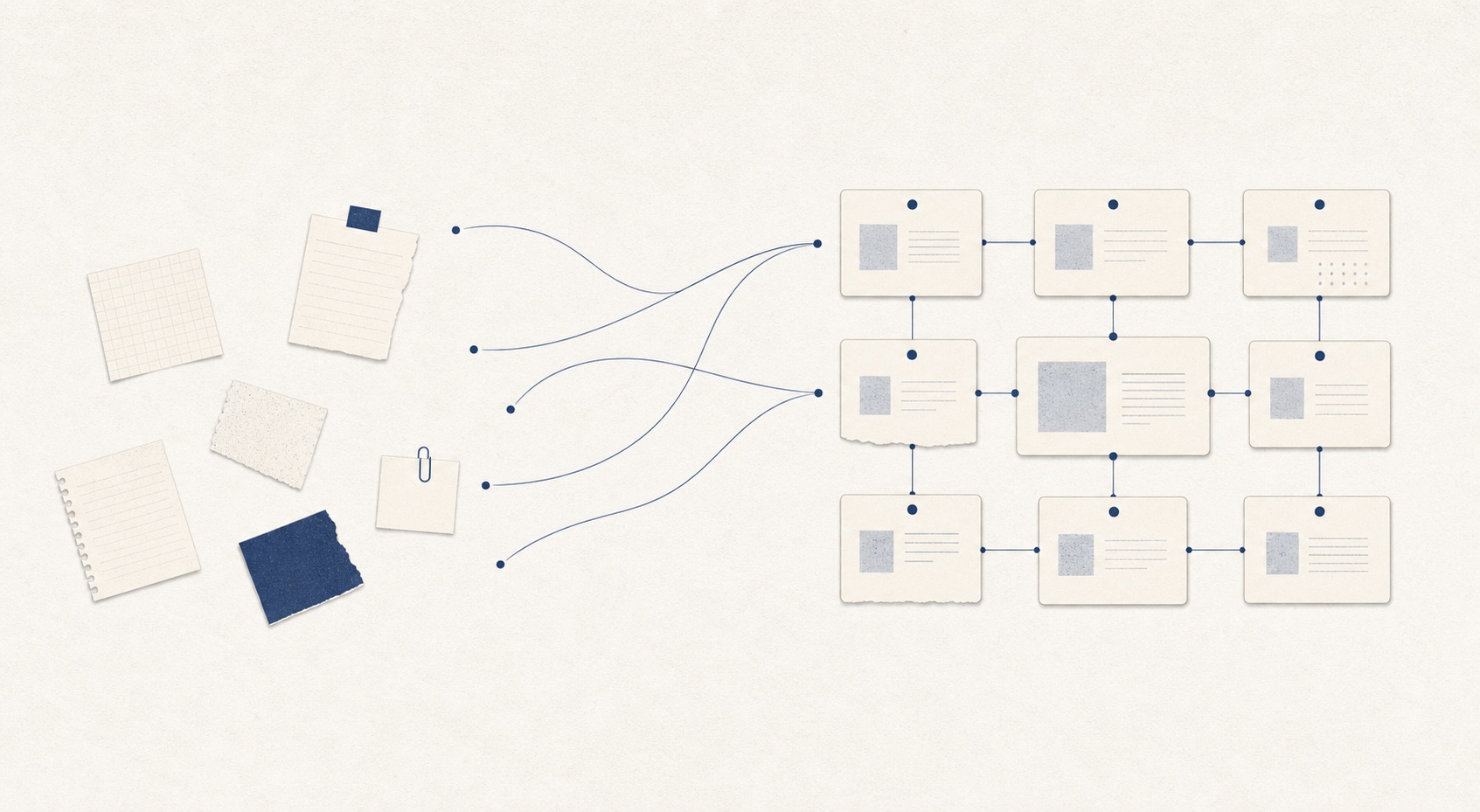
一摊散素材,交给 LLM,最后自己长成一张互相连接的网。
我电脑里躺着几百条收藏:Twitter 书签、公众号"稍后读"、Zotero 里没翻开过的 PDF、Obsidian 里建了又荒废的几十篇笔记。素材从来不缺,缺的是有人去维护它们。
一篇文章读完,得给它写个摘要,跟已有的笔记建上联系,再翻出三个月前那篇观点打架的旧文标一句"这里有矛盾"——这些活又碎又烦,我坚持两周就放弃了。笔记软件换了一轮又一轮,最后都长成了垃圾场。
Karpathy 去年四月那条推(1900 万阅读)正好点破这件事:
The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping... Humans abandon wikis because the maintenance burden grows faster than the value.— Andrej Karpathy
(维护知识库累人的不是读、也不是想,是那些记账式的杂务……人之所以放弃 wiki,是因为维护成本涨得比它带来的价值还快。)后半句才是关键:LLM 不会烦,不会忘记更新某个交叉引用,一遍能改十五个文件。所以——把那些杂活整个甩给它。
我照这个思路搭了大半年,这篇讲怎么搭。它不是我发明的,是 Karpathy 在 2026 年 4 月用"LLM Wiki"这个说法带火的模式;我做的只是把它在 Claude Code + Obsidian 上落地,并踩出一套自己的规矩。
先建立一个心智模型:三层 + 一句话分工
整套东西只有三层,记住它你就懂了一大半:
- raw/ — 原始素材。文章、论文、推文、数据、图片。这是你的真相之源,LLM 只读不写。
- wiki/ — LLM 生成和维护的
.md:实体页、概念页、综述、索引。这层 LLM 完全拥有,你基本不手写。 - schema — 一份规则文件(Claude Code 用
CLAUDE.md,Codex 用AGENTS.md),告诉 LLM 这个库怎么组织、扔素材时怎么处理、提问时怎么答。这是你和 LLM 一起慢慢养出来的配置。
Karpathy 有个比喻我很喜欢,一句话把角色分清了:
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.— Andrej Karpathy
你打开 Obsidian 看,LLM 在另一边写。分工就一句话:人负责选素材、提问题、定方向;LLM 负责全部 bookkeeping——摘要、交叉引用、归档、一致性维护。
三层结构 + 四个动作 + 人机分工:人扔素材、提问、定方向,LLM 把素材编译进 wiki 并一直维护它。
跟 RAG 的区别就藏在这张图里。RAG 是你每次提问,它现去原始文档里捞相关片段拼答案,什么都不沉淀;这套是 LLM 读完素材一次性编译进 wiki,之后持续维护——交叉引用早写好了,矛盾早标出来了,综述里已经反映了你读过的一切。用 Karpathy 的话说,wiki 是个"持续累加的资产"(compounding artifact)。这个对比值得单独说,我放到下一篇《为什么》里展开。
动手搭:三步起步
第一步,装两样东西:Claude Code 和 Obsidian。
Claude Code 官方推荐原生安装脚本(装完会自动更新)。macOS / Linux:
(Windows 在 PowerShell 里跑 irm https://claude.ai/install.ps1 | iex;也可以 brew install --cask claude-code,或者 npm i -g @anthropic-ai/claude-code——最后这种要先有 Node 18+。)装完敲 claude --version 验证。第一次随便在哪个目录敲 claude,它会拉起浏览器让你登录,用 Claude 的 Pro / Max 订阅账号就行(免费版用不了)。在中国大陆得先挂代理:export HTTPS_PROXY=http://127.0.0.1:7890(换成你自己的地址)再启动。平时要用,就 cd 到知识库目录、敲一句 claude 进去,它自动读当前目录的文件。
Obsidian 去 obsidian.md 下载安装,打开后选 "Open folder as vault",指向你那个知识库文件夹。这下就凑齐了 Karpathy 说的那个画面:你在 Obsidian 里浏览,Claude Code 在终端里写。
有两个 Obsidian 设置建议一上来就配好:
- 让图片落到本地:Settings → Files and links 里把 "Attachment folder path" 设成固定目录(比如
raw/assets);再到 Settings → Hotkeys 搜 "Download",给 "Download attachments for current file" 绑个快捷键。抓完一篇文章按一下,图就全下到本地——这样 LLM 才能直接看图,而不是依赖随时会断的外链。 - 装 Web Clipper:Obsidian 官方的浏览器扩展,网页一键转成 markdown 存进
raw/。
第二步,建最小骨架。 不用一开始就上复杂结构,四个东西就能跑:
第三步,写 CLAUDE.md——这是整套东西的灵魂。 它决定了 LLM 是一个守规矩的 wiki 维护者,还是一个随便聊聊的 chatbot。下面是一个能直接抄的精简版:
抄完按你自己的领域改。我的完整版长得多(七条 workflow + 一堆硬约束),但那是大半年长出来的,不是一开始就有的——schema 是养出来的,不是设计出来的。
举个例子:我一开始让 LLM 读完素材直接写 wiki,结果它老抓错重点、写一堆我不在意的东西。后来我加了一条规矩——ingest 时先用三句话跟我对齐"新东西是什么、跟已有的页什么关系",我点头了再动笔。就这一条,产出立刻顺了。规矩都是这么遇到一个麻烦、补一条,慢慢攒出来的。
顺带一提,这套模板在中英社区已经被抄烂了:中文有 Miles 的零基础教程,英文有 Yarchi 那篇 400 万阅读的 "AI Second Brain",还有人拿它跑投资研究工作流。你不是第一个搭的,可以放心抄。
跑起来:三个核心动作
搭好了,日常就围着三个动作转。
Ingest——扔素材。 我把一篇文章丢给 Claude Code,它会:读一遍 → 跟我对一下要点 → 把原文存进 raw/ → 在 wiki/ 写摘要页 → 然后扩散:找出相关的实体页、概念页挨个更新。一个源经常会 touch 十到十五个文件,这正是人懒得干、LLM 不嫌烦的部分。
举个例子。我扔一篇讲"知识引擎"的公众号文章进去,Claude Code 会先读一遍、跟我对几句要点——它跟已有的页什么关系、有没有新东西,然后把原文存进 raw/、新建一页摘要,再顺手更新几个相关的概念页:可能一页记着它和我这套方法的差异,一页是同类产品的对比。最后在 log.md 追加一行:日期、来源、碰了哪几页、有没有矛盾或新洞察。整个过程我只看、只点头,一个字没手写。这就是"扩散"——一个源落进来,相关的页跟着一起长。
我给这一步配了几个 skill 省事:抓公众号用 wechat-ingest、抓推文用 twitter-ingest、图片本地化和上图床用 markdown-image-hosting。有个细节值得专门说——抓回来的文章里的图,要下载到本地,LLM 才能"看"图(架构图、数据表截图里的信息往往是文章精华)。Karpathy 原文里也强调了这点:
it lets the LLM view and reference images directly instead of relying on URLs that may break.— Andrej Karpathy
Query——提问。 LLM 先读 index.md 定位到候选页,再读页面和它们的交叉引用,最后带着引用合成答案。关键的一招是:有价值的答案要 file 回 wiki。你随手问出来的一张对比表、一段分析,别让它消失在聊天记录里——存成 wiki 的新页,这样你的每一次探索都在给库加料。
比如问它一句"我收集的这些做法,哪些冲着 AI 编码、哪些是纯知识管理",它会翻 index.md 里相关的七八页,给一张分类表,每行挂着来源页链接。这张表本身有用,就把它存成新的一页——下次再问相关问题,直接读这页,不用重新捋一遍。
Lint——体检。 库大了会长毛病,定期让 LLM 扫一遍:哪两页说法打架了、哪页被新素材推翻了、哪页成了没人链接的孤儿、哪个概念被反复提到却没有自己的页。它给你一份报告,你来定哪些要改。
我在这三个之外还加了几条:轻量的 journal(随手记一条备忘,不走完整 ingest)、idea(半成品想法先进草稿、稳定了再进 wiki)、research-to-ingest(库里没料时先研究、筛选、批判性分析,再选择性入库)、还有专门的 writing(写博客——比如这篇)。这些都是 Karpathy 原版没有、我按自己需要加的。
工具链和一些小技巧
用下来真正有用的几样:
- Obsidian 的 graph view——看你的库长什么形状最直观:哪些页是枢纽、哪些是孤儿,一眼就看出来。
- Web Clipper——Obsidian 官方扩展,把网页一键转成 markdown 进
raw/。 - index.md vs log.md——前者是内容目录(按类别组织),后者是时间线(append-only,每条以
## [YYYY-MM-DD] type | 标题开头,这样grep就能查最近动了什么)。在大概一百多页的规模内,光靠这两个文件定位就够了,不需要上 embedding、上 RAG 那套基础设施;再大了再考虑接 qmd 这类本地搜索。 - 它就是个 git repo——一堆 markdown 而已。版本历史、回滚、分支,全白嫖。
- 把重复流程封装成 skill——抓取、图床、研究、发博客,跑顺了就固化成一个 skill,下次一句话调用。
几条让它长期不崩的规矩
教程层面点到为止,每一条背后的故事我留到下一篇讲。但有几条规矩,从第一天就该立:
- raw/ 必须是原文(verbatim)。 存进去的东西只能加 frontmatter、换个图床链接,绝不能让 LLM 顺手"优化"几句。因为 raw 是真相之源,一旦它在保存时就改写了原文,后面所有引用和事实核查就都失去了锚点。
- 一手锚点优先。 凡是涉及"谁说的""什么数字""什么观点"这三类引用,必须抓回一手原文,不能只靠二手转述写结论。二手转述特别爱把客座作者的话安到站长头上、把 A 文章的数据记到 B 文章名下——这个坑我踩过好几次,下一篇专门讲。
- 链接带可读标题,文件名 kebab-case,日期用 ISO。 让人看到的是有意义的标题,不是一串路径。
别想着一步到位
最后一句最重要:从最小的三层骨架开始就行。raw/、wiki/、CLAUDE.md,加 index.md 和 log.md,够你跑起来了。schema 和 workflow 是用着用着长出来的——遇到一个反复出现的麻烦,就往 CLAUDE.md 里加一条规矩,下次 LLM 就照办了。
Karpathy 那份 gist 结尾说得好,它"刻意写得很抽象",因为具体长什么样取决于你的领域、你的偏好:
pick what's useful, ignore what isn't... Your LLM can figure out the rest.— Andrej Karpathy
把那份 gist 丢给你的 agent,跟它一起搭一个适合你的版本,就是最好的开始。
至于这套东西为什么值得搭、半年下来什么真有用什么是自我感动、那些规矩到底是踩了什么坑才立的——我写在下一篇《我让 AI 管了半年知识库》里。